关于Scikit-learn机器学习的笔记——第六篇
视频教程:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习
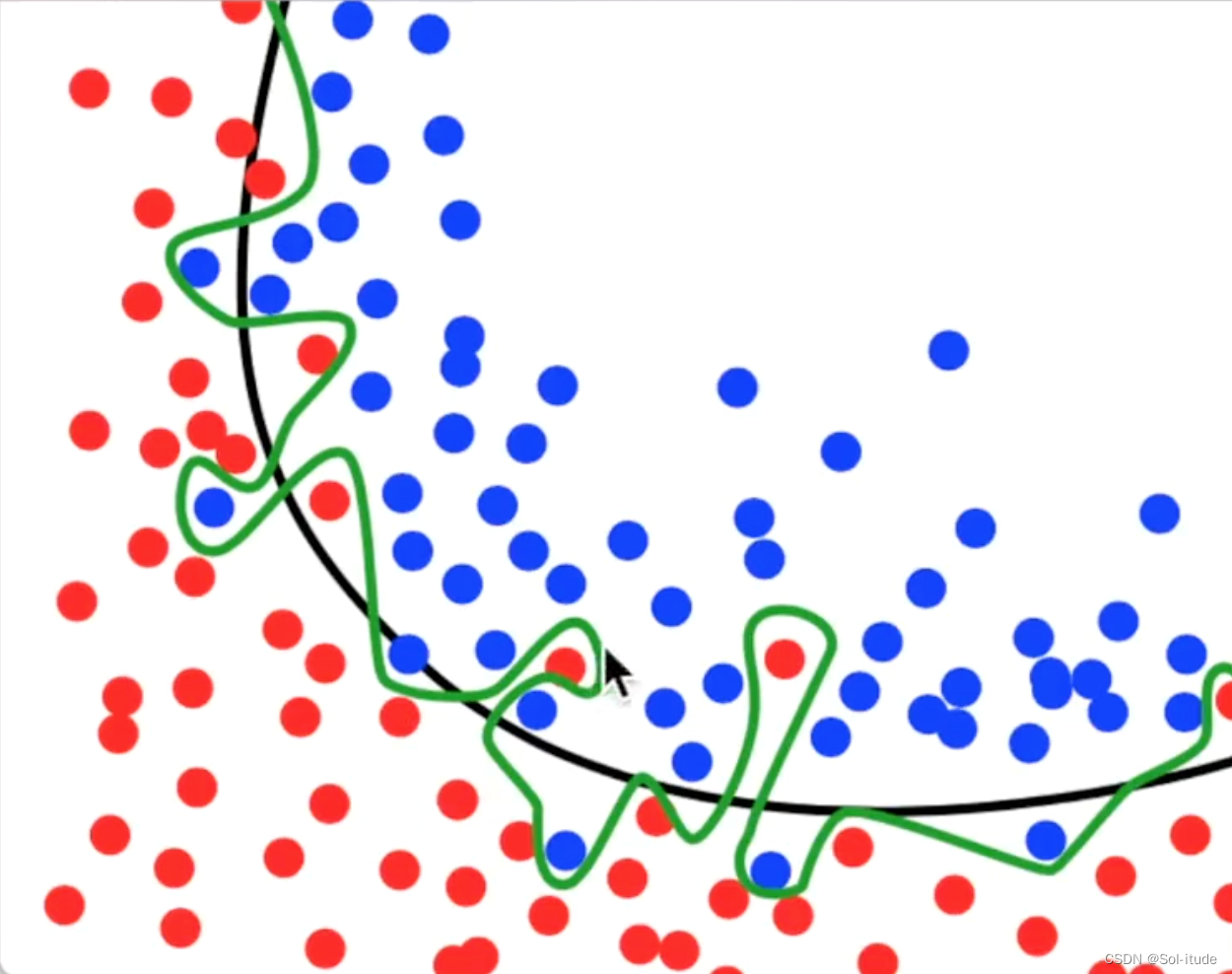
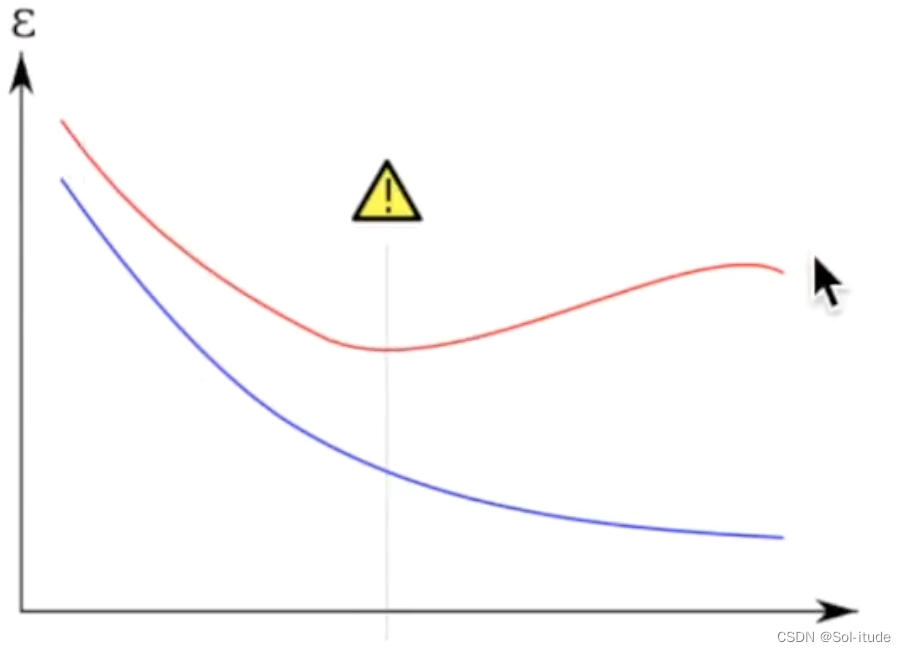
Overfitting过拟合现象
程序示例:
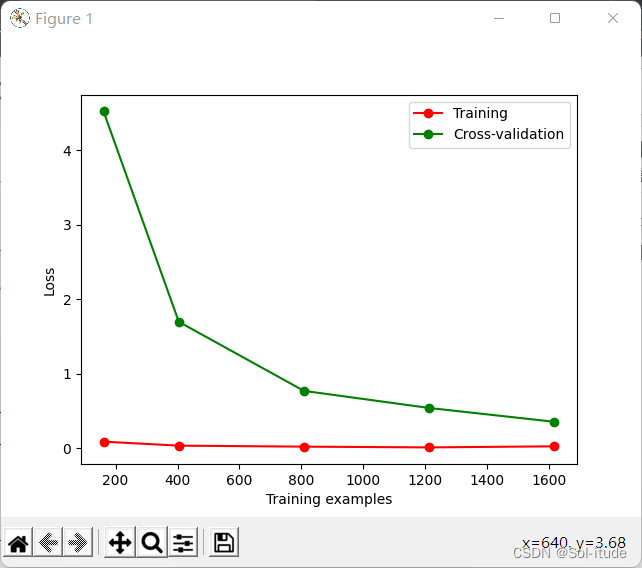
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from sklearn.model_selection import learning_curvefrom sklearn.datasets import load_digitsfrom sklearn.svm import SVCimport matplotlib.pyplot as pltimport numpy as npdigits=load_digits() X=digits.data y=digits.target train_sizes,train_loss,test_loss=learning_curve( SVC(gamma=0.001 ),X,y,cv=10 ,scoring='neg_mean_squared_error' , train_sizes=[0.1 ,0.25 ,0.5 ,0.75 ,1 ]) train_loss_mean=-np.mean(train_loss,axis=1 ) test_loss_mean=-np.mean(test_loss,axis=1 ) plt.plot(train_sizes,train_loss_mean,'o-' ,color="r" ,label="Training" ) plt.plot(train_sizes,test_loss_mean,'o-' ,color="g" ,label="Cross-validation" ) plt.xlabel("Training examples" ) plt.ylabel("Loss" ) plt.legend(loc="best" ) plt.show()
输出结果:
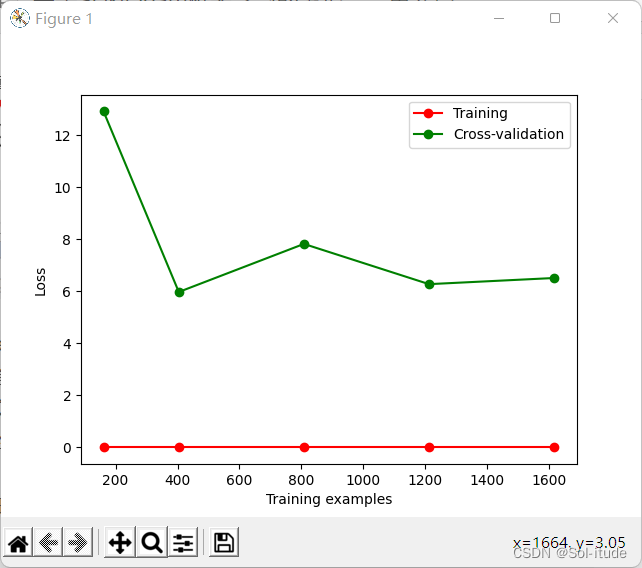
若将gamma的值改为0.01
1 2 3 train_sizes,train_loss,test_loss=learning_curve( SVC(gamma=0.01 ),X,y,cv=10 ,scoring='neg_mean_squared_error' , train_sizes=[0.1 ,0.25 ,0.5 ,0.75 ,1 ])
输出结果: