from sklearn.datasets import load_iris##从sklearn数据库导入数据 from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
from sklearn.datasets import load_iris##从sklearn数据库导入数据 from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
from sklearn.datasets import load_iris##从sklearn数据库导入数据 from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
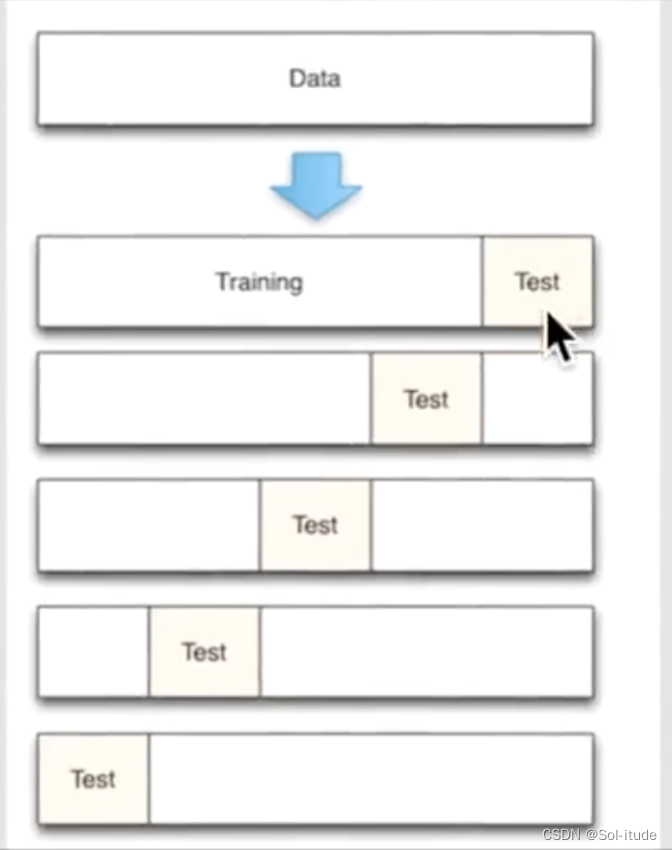
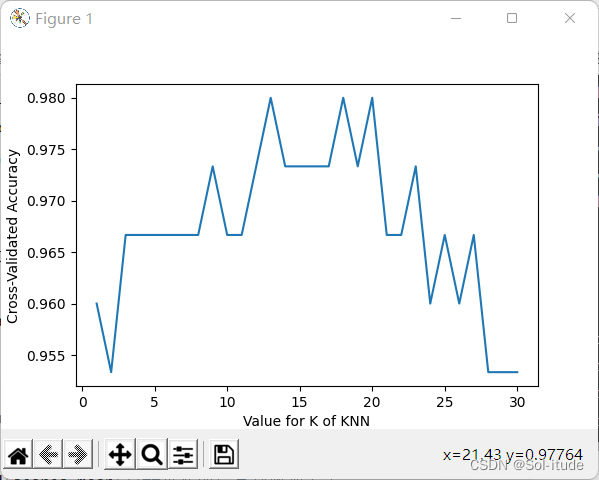
from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt k_range=range(1,31)##k的范围是1到31 k_scores=[] for k in k_range: knn=KNeighborsClassifier(n_neighbors=k)##机器学习命令,考虑学习点附近k个点的neighbor,把k从1到31都带进去 scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')##for classication #loss=-cross_val_score(knn,X,y,cv=10,scoring='mean_squared_error')##for regression k_scores.append(scores.mean())##每次的结果都附加上去 plt.plot(k_range,k_scores) plt.xlabel('Value for K of KNN') plt.ylabel('Cross-Validated Accuracy') plt.show()
from sklearn.datasets import load_iris##从sklearn数据库导入数据 from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
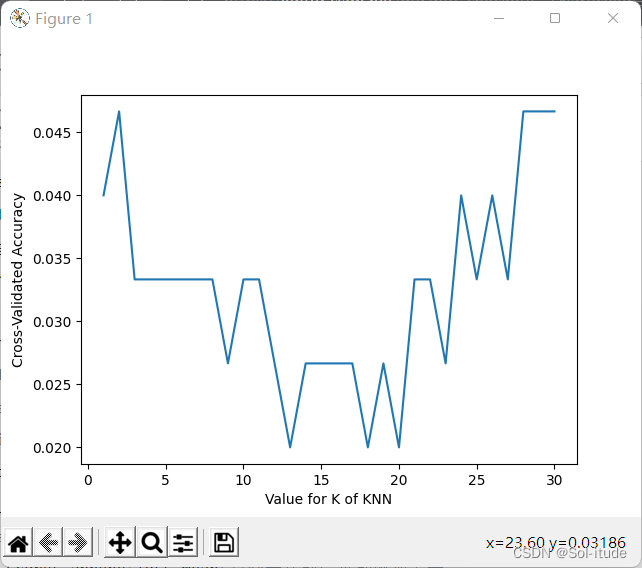
from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt k_range=range(1,31)##k的范围是1到31 k_scores=[] for k in k_range: knn=KNeighborsClassifier(n_neighbors=k)##机器学习命令,考虑学习点附近k个点的neighbor,把k从1到31都带进去,这里的模型也可以改,判断该采用什么样子的模型 #scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')##for classication,用了cv=10更精准 loss=-cross_val_score(knn,X,y,cv=10,scoring='neg_mean_squared_error')##for regression,判断误差 k_scores.append(loss.mean())##每次的结果都附加上去 plt.plot(k_range,k_scores) plt.xlabel('Value for K of KNN') plt.ylabel('Cross-Validated Accuracy') plt.show()