1.项目介绍 对于现代雷达探测系统而言,无人机和飞鸟同属于低空小、微特征的一类典型目标,而面对比较复杂的环境,如何有效区分两者类型并完成识别是当下急迫且重要的难题。常规方法是从目标的微动特征差异进行区分,但由于两者回波微弱,很难通过时频分析方法提取目标特征。针对无人机与鸟类轨迹的特性差异,我们设计了多维特征提取方法,包括轨迹角度变化、航向角振荡、速度分布等物理量,为分类模型提供了充分的信息支持。我们采用了多种主流机器学习算法的组合,通过Stacking集成学习方法,有效提升了模型的预测能力和泛化性能。本项目聚焦无人机与鸟类航迹识别的挑战,旨在通过深度分析两者在运动特性上的差异,开发一个基于特征提取和机器学习模型的低空小、微无人机识别技术。无人机和鸟类的飞行轨迹具有显著不同的动态特性,如何准确区分二者是智能监控、边境安防、航空安全、环境与生态监测等场景中的重要任务。为此,本项目采用了一套严谨的预处理与特征提取流程,并通过先进的集成学习方法提升模型的精度和泛化能力。首先对比两者在运动轨迹等信息上的差异性,进行特征分析,提出了时间相关的航向震荡频率与速度分布等特征量描述方法,利用雷达系统记录的航迹数据,提取两者的有效特征量;然后利用XGBoost算法对样本进行训练,并在获得最优模型参数后,通过测试样本进行测试,测试分类结果显示识别的准确率能够达93%,其结果表明了该方法的正确性也体现了该方法在识别中的稳定性和可靠性,具有较高的实际应用价值。
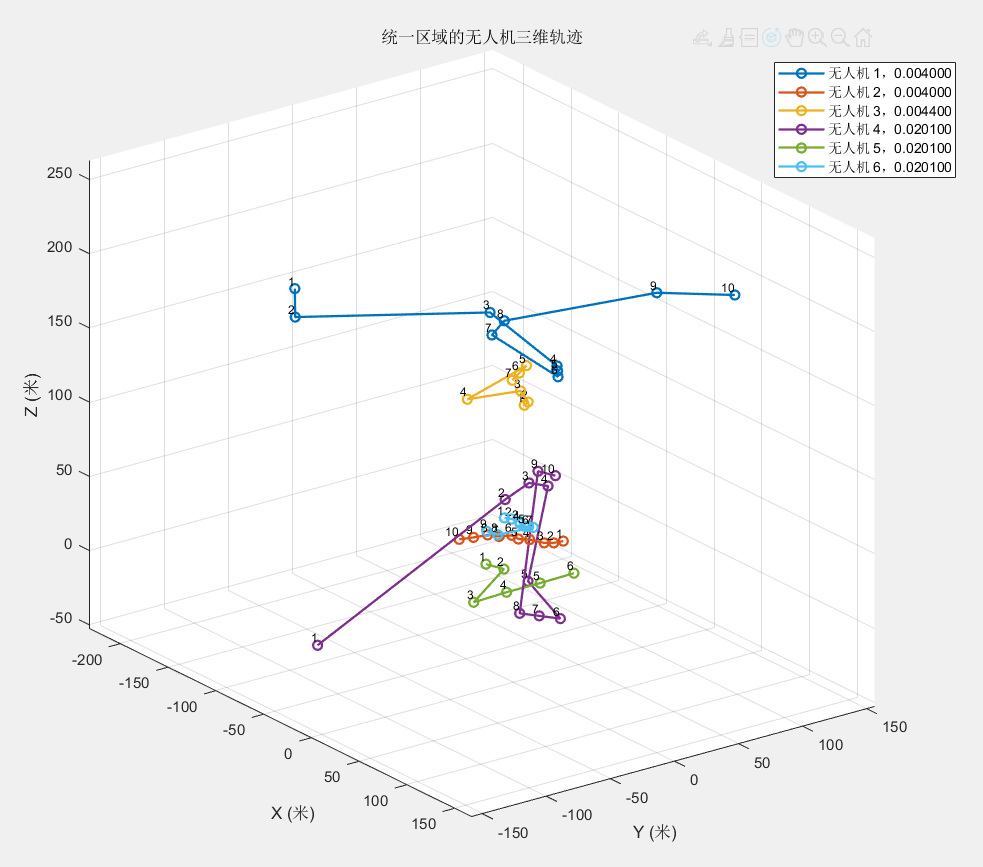
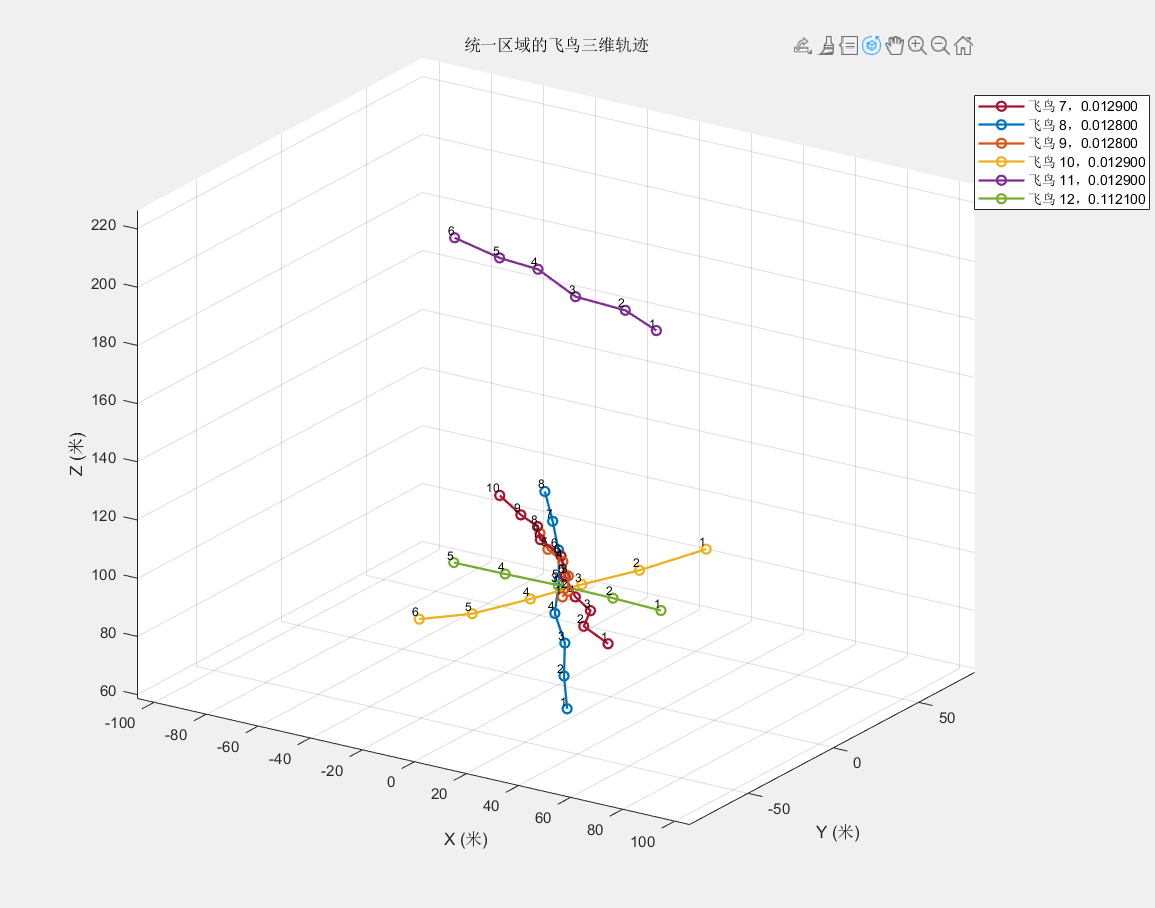
2.数据预处理 项目原始数据包含无人机和飞鸟的雷达数据信息,标签为1和0,但并不能确定1和0分别是哪一类。先将这两类的轨迹画出来,观察轨迹图,因为无人机和飞鸟的轨迹跨度较大,所以先将其统一轨迹范围后再画图,从视觉上先感受无人机合和飞鸟轨迹的区别。
由于初始数据含有较多重复数据和异常数据,所以我们需要先对初始数据进行数据清洗,数据一般在时间上都是间隔2s的,但是在一组无人机/飞鸟的数据内,可能会出现时间上的不连续,所以我们预处理代码先把这些时间间隔出现突变的数据,在标签列标记上3,在以后读取的时候,不能将含有3的这一组数据视为1组数据。下面的代码是去除数据中的重复文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 clear; clc; data = readtable ("data.xlsx" , 'ReadVariableNames' , false , 'Range' , 'A:G' ); column7_data = data{:, 7 }; if iscell(column7_data) column7_data = str2double(column7_data); end column7_data(end +1 ,:) = 0 ; output_data = cell(size (column7_data)); azimuth = data{:, 1 }; range = data{:, 2 }; relative_height = data{:, 3 }; labels = data{:, 7 }; RCS = 1000 * data{:, 6 }; vel_jingxiang = data{:, 4 }; time = data{:, 5 }; if iscell(labels) labels = cellfun (@str2double, labels); end start_indices = find (~isnan (column7_data)); all_data_segs = table (); for i = 1 :length (start_indices) - 1 current_start = start_indices(i ); current_end = start_indices(i + 1 ) - 1 ; data_seg = data(current_start:current_end, :); data_without_labels = data_seg(:, 1 :6 ); [~, unique_idx] = unique(data_without_labels, 'rows' , 'stable' ); duplicate_rows = setdiff(1 :size (data_without_labels, 1 ), unique_idx); num_duplicates = length (duplicate_rows); data_seg(duplicate_rows, :) = []; empty_rows = table (zeros (length (duplicate_rows),1 )*NaN, ... zeros (length (duplicate_rows),1 )*NaN, ... zeros (length (duplicate_rows),1 )*NaN,... zeros (length (duplicate_rows),1 )*NaN, ... zeros (length (duplicate_rows),1 )*NaN, ... zeros (length (duplicate_rows),1 )*NaN, ... zeros (length (duplicate_rows),1 )*NaN); if num_duplicates > 0 data_seg = [data_seg; empty_rows]; end all_data_segs = [all_data_segs; data_seg]; end writetable (all_data_segs, 'data_test_chongfu.xlsx' );
经过去重操作后,给时间超出阈值的数据标记为3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 clear; data = readtable ('data_test_chongfu.xlsx' ); azimuth = data{:, 1 }; range = data{:, 2 }; relative_height = data{:, 3 }; v_h = data{:, 4 }; time = data{:, 5 }; RCS = data{:, 6 }; labels = data{:, 7 }; time_threshold = 20 ; tolerance = 0.2 ; count4 = 0 ; count6 = 0 ; count8 = 0 ; count10 = 0 ; count_outrange = 0 ; count_1_8 = 0 ; count_dt2 = 0 ; data.DeltaTime2 = NaN(height(data), 1 ); matching_deltas = {}; if iscell(labels) labels = str2double(labels); end labels(end +1 ,:) = 0 ; if isdatetime(time) time = seconds(time - time(1 )); end start_indices = find (~isnan (labels)); delta_ts = zeros (height(data), 1 ); for i = 1 :length (start_indices) - 1 current_start = start_indices(i ); current_end = start_indices(i + 1 ) - 1 ; group_time = time(current_start:current_end); group_labels = labels(current_start:current_end); angle_exceeded = false ; angle_exceeded_4 = false ; angle_exceeded_6 = false ; angle_exceeded_8 = false ; angle_exceeded_10 = false ; for j = 2 :length (group_time) delta_t = group_time(j ) - group_time(j - 1 ); delta_ts(current_start + j - 1 ) = delta_t; if ~angle_exceeded && abs (delta_t) > time_threshold labels(current_start + j - 1 ) = 3 ; count_outrange = count_outrange + 1 ; angle_exceeded = true ; end if ~angle_exceeded && abs (delta_t) < 1.8 count_1_8 = count_1_8 + 1 ; angle_exceeded = true ; end if ~angle_exceeded && abs (delta_t - 2 ) < time_threshold if abs (delta_t - 2 ) > 3 DeltaTime2(current_start + j - 1 ) = 4 ; count_dt2 = count_dt2 + 1 ; angle_exceeded = true ; end end if ~angle_exceeded_4 && abs (delta_t - 4 ) < tolerance count4 = count4 + 1 ; angle_exceeded_4 = true ; matching_deltas{end + 1 , 1 } = current_start + j - 1 ; matching_deltas{end , 2 } = delta_t; end if ~angle_exceeded_6 && abs (delta_t - 6 ) < tolerance count6 = count6 + 1 ; angle_exceeded_6 = true ; end if ~angle_exceeded_8 && abs (delta_t - 8 ) < tolerance count8 = count8 + 1 ; angle_exceeded_8 = true ; end if ~angle_exceeded_10 && abs (delta_t - 10 ) < tolerance count10 = count10 + 1 ; angle_exceeded_10 = true ; end end end disp ("测试数据超出时间间隔阈值的轨迹有:" );disp (count_outrange);disp ("测试数据的时间间隔小于1.8秒的轨迹有:" );disp (count_1_8);disp ("测试数据的时间间隔在4秒左右的轨迹有:" );disp (count4);disp ("测试数据的时间间隔在6秒左右的轨迹有:" );disp (count6);disp ("测试数据的时间间隔在8秒左右的轨迹有:" );disp (count8);disp ("测试数据的时间间隔在10秒左右的轨迹有:" );disp (count10);disp ("测试数据的时间间隔大于3秒小于20秒的轨迹有:" );disp (count_dt2);labels([23170 ],:) = []; labels = num2cell (labels); data{:, 7 } = labels; output_filename = 'data_test_chongfu_biao3.xlsx' ; writetable (data, output_filename);disp (['数据已保存至 ' , output_filename]);
然后给这些处理过的数据做标记,因为在这里我们认为含有3的数据是重新开始的一组无人机/飞鸟数据,所以我们在这里对整体的数据进行标记,其中把正常标签和标签3的数据都做标记,按顺序往下标号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 clear; data = readtable ('data_test_chongfu_biao3.xlsx' ); azimuth = data{:, 1 }; range = data{:, 2 }; relative_height = data{:, 3 }; v_h = data{:, 4 }; time = data{:, 5 }; RCS = data{:, 6 }; labels = data{:, 7 }; data.DroneNum = NaN(height(data), 1 ); data.startline = NaN(height(data), 1 ); data.endline = NaN(height(data), 1 ); time_threshold = 2.5 ; tolerance = 0.2 ; count4 = 0 ; count6 = 0 ; count8 = 0 ; count10 = 0 ; count = 0 ; droneNum = 1 ; combinedData = []; matching_deltas = {}; count_31 = 0 ; if iscell(labels) labels = str2double(labels); end labels(end +1 ,:) = 0 ; if isdatetime(time) time = seconds(time - time(1 )); end start_indices = find (~isnan (labels)); start3_indices = find (labels == 3 ); delta_ts = zeros (height(data), 1 ); data.begin30 = NaN(height(data), 1 ); for i = 1 :length (start3_indices) - 1 current3_start = start3_indices(i ); data.begin30(current3_start) = 1 ; count_31 = count_31 + 1 ; end for i = 1 :length (start_indices) - 1 current_start = start_indices(i ); current_end = start_indices(i + 1 ) - 1 ; empty_rows = find (isnan (azimuth(current_start:current_end))); if ~isempty (empty_rows) current_end = current_start + empty_rows(1 ) - 2 ; end azi = azimuth(current_start:current_end); data.DroneNum(current_start) = droneNum; droneNum = droneNum + 1 ; data.startline(current_start) = current_start; data.endline(current_start) = current_end; nan_count = sum(isnan (azimuth(current_start:current_end))); data.endline(current_start) = current_end - nan_count; datatemp = data(current_start:current_end, :); combinedData = [combinedData; datatemp]; end disp ("测试的轨迹共有:" );disp (length (start_indices))disp ("从标签3到下一个标签的轨迹有:" );disp (count_31);disp ("纯的标签轨迹占比:" );disp ((length (start_indices)-count_31)/length (start_indices));save combinedData.mat;
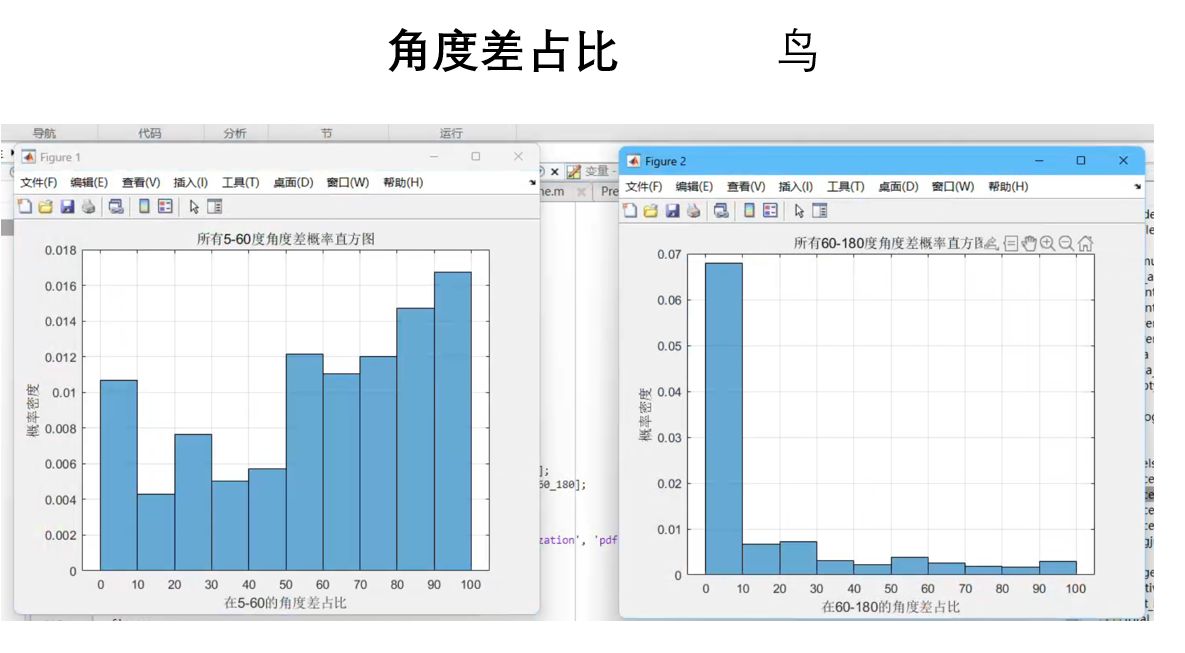
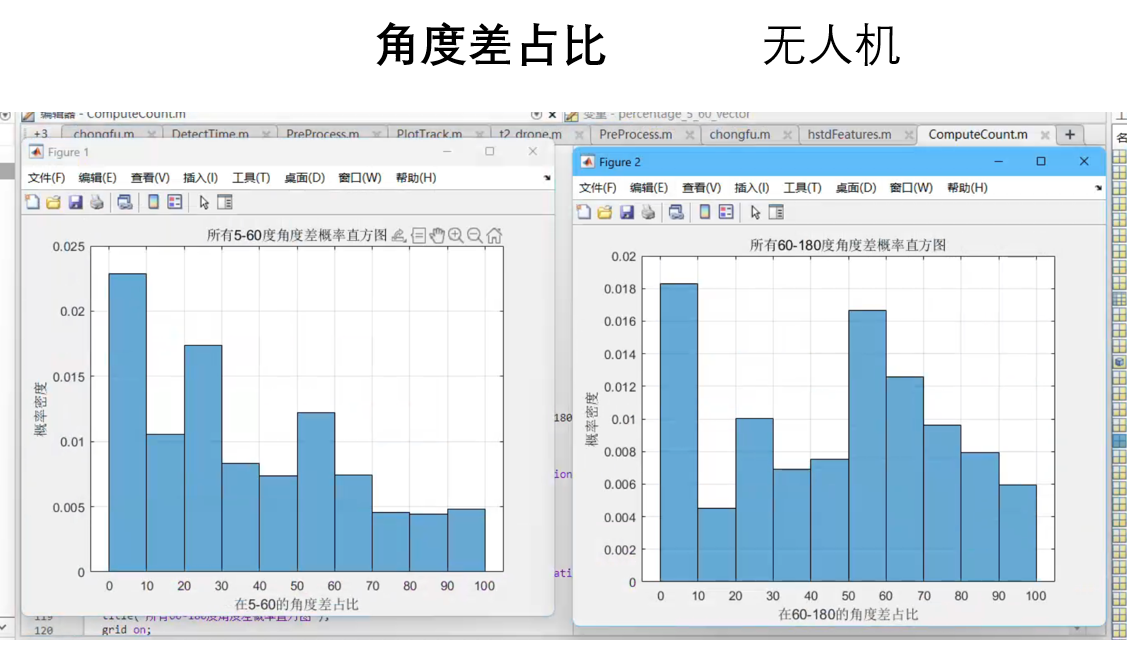
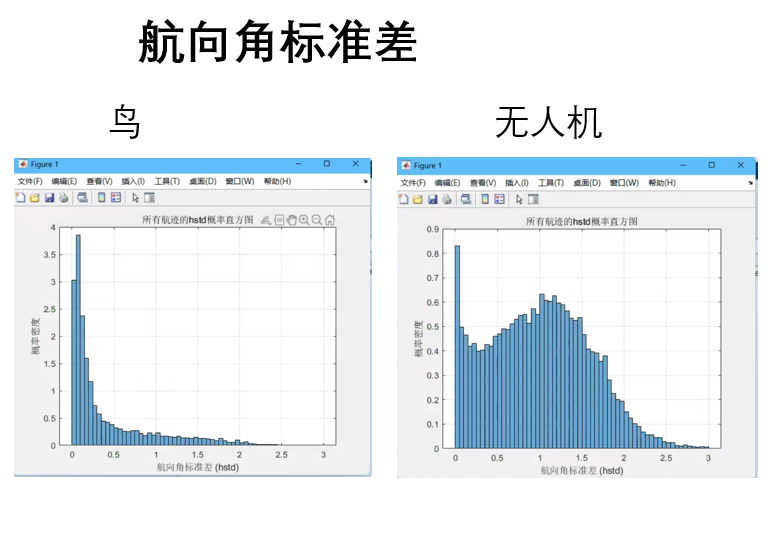
3.特征选取 不论是用深度学习的方法还是机器学习等方法,都需要进行特征提取,所以我们需要根据已知信息来提取特征,目前已知信息有物体的目标方位角、目标斜距、相对高度、径向速率、记录时间、RCS这几个物理量,我们首先通过观察三维空间下的无人机和飞鸟的轨迹,确定几个物理量,然后画出其二维直方图
仅仅选取这几个物理量是不够的,我们还需要选取,为了更科学的选取,我们从一些论文中选择了部分物理量作为特征值
剩下就不一一列举了。
4.模型训练 在选取好特征之后,就可以进入模型训练了,一开始我们试验了一些经典的模型例如决策树、随机森林、SVM等效果都不是特别好,后来又尝试了Adaboost
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 optOptions = struct('AcquisitionFunctionName' , 'expected-improvement-plus' , ... 'MaxObjectiveEvaluations' , 30 , ... 'Kfold' , 5 ); classWeights = [majority_class_size / minority_class_size, 1 ]; net = fitcensemble(p_train, t_train, ... 'Method' , 'AdaBoostM1' , ... 'Learners' , 'tree' , ... 'NumLearningCycles' , 50 , ... 'OptimizeHyperparameters' , 'auto' , ... 'Weights' , classWeights(t_train), ... 'HyperparameterOptimizationOptions' , optOptions); disp (net);
得到了初步的结果
后续在实际的测试中表现不佳,正确率就在70%左右,于是又去尝试了Xgboost,最后得到的效果较好,95%左右。
参考文献
[1]刘佳,徐群玉,陈唯实.无人机雷达航迹运动特征提取及组合分类方法[J].系统工程与电子技术,2023,45(10):3122-3131.