
这是为了准备国赛突击学习的模型算法,我在原有的基础上加上自己的理解虽然不知道对不对,就是为了记录下自己学的模型他究竟是个什么东西,语言通俗,但是极不准确,只适合做一个大概的了解,建议大家详细的还是要看更专业的文章去学习,但是自己看着还是挺顺眼的,欢迎批评指正,里面我说的程序包就是老哥提供的程序包
视频来源:泰山教育小石老师数学建模教程
【零基础教程】老哥:数学建模算法、编程、写作和获奖指南全流程培训!
ahp决策比较

c1/c2为4表示c1比c2更加重要,如果是数值小于1,则表示其c1没有c2重要
z表示旅游选择要去的目的地,a1,a2,a3,a4,a5表示五个不同的考虑因素,例如,饮食,费用,居住等,b1,b2,b3表示旅游要去的地点

2.层次分析法算法用于多个元素之前,有多个决策条件,决策条件所占的比重不同,根据不同的比重,比较出最符合题目要求的结果;
3.多属性决策模型也是和层次分析算法一样,也是进行多属性元素的决策;
4.比较完多个矩阵后,得到的值,A的矩阵中的值,分别与B1,B2等中的对应第一个数乘起来,才是最终的比较结果
层次分析法使用方法
把代码直接复制到Matlab的命令行中,然后输入判决矩阵A,注意A一定要满足逻辑,不然一致性检验会不通过
插值与拟合
插值与拟合代码使用方法
数据之间有空缺,我们利用代码进行补全
1 | 一维插值步骤 |
1 | 二维插值步骤 |
1 | 多项式拟合步骤 |
灰色预测模型
1.灰色预测模型是通过少量的、不完全的信息,建立出数学模型,并做出预测的一种预测方法,预测是根据过去和现在的发展规律,借助科学的方法对其未来趋势进行预测,描述和分析。
2.运用GM(1,1)的方法对数据进行预测,得出的结果需要检验,检验表格如下
最后拟合出数据的下一个值和下下个值
灰色预测使用方法
1 | 灰色预测步骤 |
dijkatra模型
最短路径问题求解
weight= [0 2 8 1 Inf Inf Inf Inf Inf Inf Inf;
2 0 6 Inf 1 Inf Inf Inf Inf Inf Inf;
8 6 0 7 5 1 2 Inf Inf Inf Inf;
1 Inf 7 0 Inf Inf 9 Inf Inf Inf Inf;
Inf 1 5 Inf 0 3 Inf 2 9 Inf Inf;
Inf Inf 1 Inf 3 0 4 Inf 6 Inf Inf;
Inf Inf 2 9 Inf 4 0 Inf 3 1 Inf;
Inf Inf Inf Inf 2 Inf Inf 0 7 Inf 9;
Inf Inf Inf Inf 9 6 3 7 0 1 2;
Inf Inf Inf Inf Inf Inf 1 Inf 1 0 4;
Inf Inf Inf Inf Inf Inf Inf 9 2 4 0;];
[dis, path]=dijkstra(weight,1, 11)
1为起始点,11位终点,根据所给的图形列出矩阵模型,用vi,与
vj进行比较
从起点数组(S)开始,遍历周围的点,从这些点(数组U)中找到距离最短的点,放入起点数组(S)中,就是这样的过程
dijkatra模型使用方法
1 | 可以使用图论软件进行计算 |
floyd算法
计算最短路径问题
制作好加权距离矩阵,然后写进tulun的m中,用这个算法的时候,可以用dijistra喝floyd两种算法,经过比较,用最合适的
模拟退火模型
用来解决tsp问题,就是一个旅行商要拜访n个城市,要走的路径是每个城市只能拜访一次,而且最后要回到出发的城市,路径选择的目标是要求得路径路程为所有路径之中的最小值。
需要更改的的只有tsp.m里面的城市坐标参数
模拟退火算法主要用于难以准确求出具体的解的问题之中。通过多次迭代,它可以不断地接近最优解。每次求解可能的结果可能都不一样,因为是在不断趋于最优解的。
就是在随机中找到全局的最优解,和爬山算法不同,爬山算法找不到全局的最优解,只能找到部分区间的最优解。
模拟退火使用方法
例子
1 | 求目标函数f(x)=x1^2+x2^2+8在x1^2-x2>0;-x1-x2^2+2=0约束下的最小值问题 |
1 | 1.复制代码 |
在这里修改程序参数
1 | %产生随机扰动(3)新解的产生 |
1 | %检查是否满足约束 |
1 | %退火过程 |
种群竞争模型
表示两个种群在竞争后的结果
这是初始条件的配置
1 | function dx=fun(t,x,r1,r2,n1,n2,s1,s2) |
这是进行运算
1 | h=0.1;%所取时间点间隔 |
若要使物种同时存活,主要是改变s1,s2的数值,才能改变竞争的结果,且s1<1,s2<1
排队论
现实生活中的排队现象
排队过程是一个随机过程

1.顾客的输入过程
2.排队结构和排队规则,列间转移的意思是:我排这个队的时候,发现另一个队列人更少,所以我去排另一个了
3.服务结结机构和服务规则
系统运行指标参数,用来评价排队系统的优劣
- 队长:系统中的顾客数,包括被服务的顾客和正在排队的顾客
- 排队长:系统中等待服务的顾客数
- 逗留时间:指一个顾客在系统中的所有时间
- 等待时间:一个顾客在系统中的排队等待时间
- 服务强度:

M/M/1排队系统
M/M/S排队系统
1 |
|
排队论使用方法
1 | 步骤: |
主成分分析法
根据spss进行数据分析,结合多个因素,对一个因素进行分析,例如:对对各城市进行分析,通过城市的多项数据,结合spss计算出F1和F2,最后将F1和F2相加,算出总F,将F排序,得出最终结果。
主成分分析降维使用方法
1 | PCA步骤: |
聚类分析
聚类分析不必事先给出分析的标准,从样本出发,自动进行分析。
进行spss进行分析,主要看的是树状图,冰柱图直接放到论文里面就行,没那么重要
聚类分析使用方法
3种聚类方法区别不大,直接把函数导入进行使用就好
多元回归分析
为了了解多个变量之间是否相关。
虽然自变量和因变量之间没有严格的、确定的函数关系,但可以设法找出最代表他们的数学关系。

BP神经网络模型
关于这个模型我实在不是很理解,所以只能进行一下粗略的阐述,我感觉其实就是用来分类的,将多种元素进行分类 。(上面是我一年前说的话了)这个暑假我又入坑了机器学习,自己也搭建了几个神经网络,他这里说到的BP神经网络的核心其实就是这个BP,反向传播,在python里面我记得有个优化器直接就叫反向传播,这个神经网络分为前向传播和反向传播,反向传播太详细的我也说不清,大概意思就是使每一个神经元更准确
神经网络更多的是用来解决分类问题,但不同于SVM那些,如果数据互相穿插的很多,那SVM会出现过拟合,行不通,所以这个神经网络就是你输入一些数据进行学习,学习几轮之后,再输进去要预测的数值进行分类,现在Matlab的Classification应该是没有python的全,到时候如果能用python做尽量用python
BP神经网络模型使用方法
选择神经网络的判断指标可以由层次分析法进行精确筛选,比如一开始有10个指标,然后利用层次分析法选5个出来,再利用神经网络这5个指标的数据进行分类,结果会更精确
1 | P的每一行代表一个指标,每一列代表一个元素 |
Performance表示误差,误差小表示其模型合理;
Training State表示中间参数的运转过程;
看最后的结果和谁更接近,如果接近-1就是-1的类,如果接近1就是1的类。
遗传算法
求某一个函数的极值问题,解决规划问题中最大值和最小值的关系;
遗传算法的使用方法
例子
1 | % 求下列函数的最大值 % |
SVM分类器
在高维空间进行分类
SVM分类器使用方法
1 | 1.先给出分类样本进行学习 |
1 | %更新部分值 |
但我这里更推荐py的算法,直接导入数据就好
K-means算法
先定义一个类,找到类的中心点,然后再判断样本离每个中心点的距离,将这些点在都判断完之后,形成一个大的类,形成大的类以后再重新计算中心点,再将这些中心点进行比较,以此类推。
K-means算法使用方法
在演示数据中导入自己的数据,然后执行程序
1 | %演示数据 |
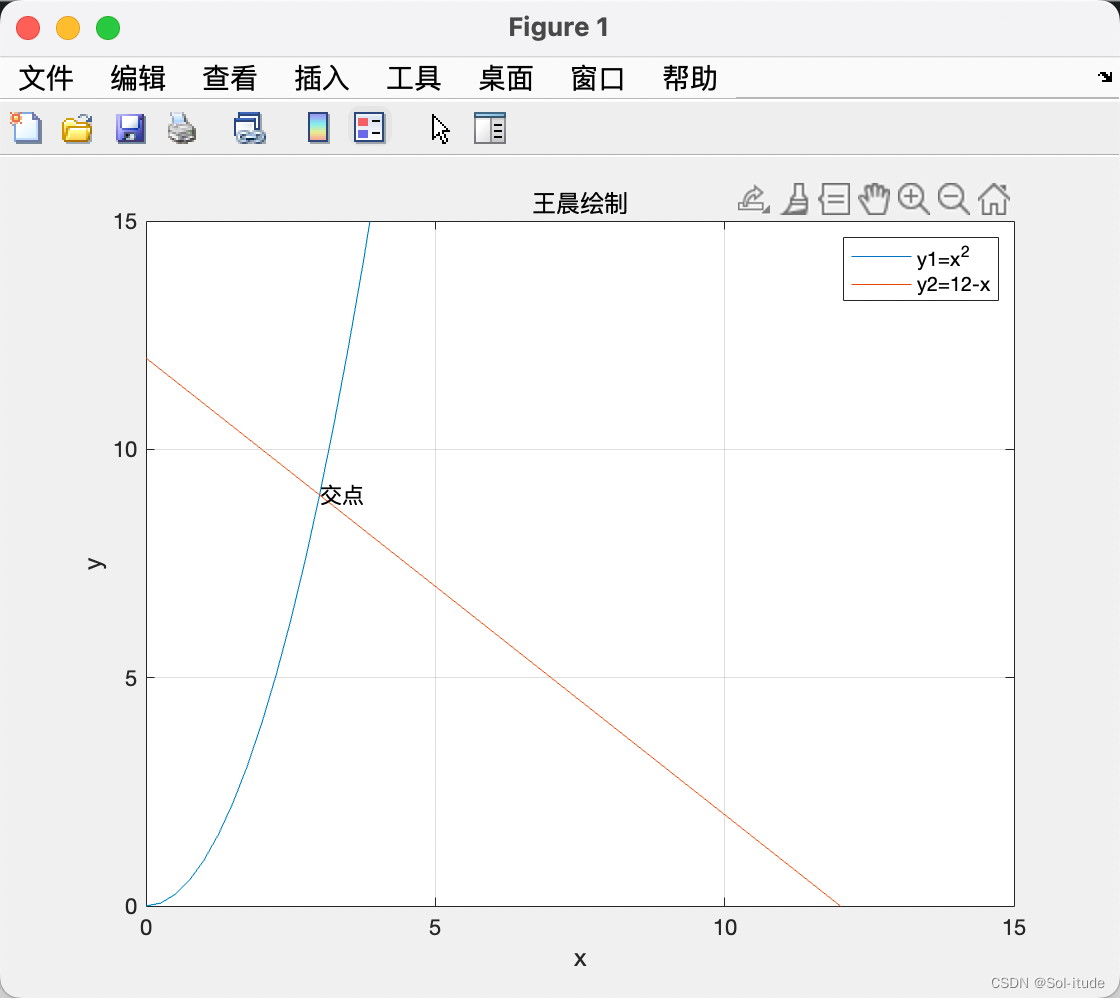
蒙特卡洛算法模拟
用大量的数据实现一些确定性问题的计算,通过计算交点下的面积占一个矩形的比例,计算其面积。
蒙特卡洛算法使用方法
1 | 蒙特卡洛法是经过大量事件的统计结果来实现一些确定性问题的计算。 |
Topsis算法
基于归一化后的原始数据矩阵,采用余弦法找出有限方案中的最优方案和最劣方案(分别用最优向量和最劣向量表示),然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。
根据一个矩阵和一个标准矩阵对比,评价哪个矩阵是最好的
Topsis算法使用方法
1 | 构建好矩阵直接执行程序就OK |
回归预测分析
提供一定的原始数据,执行模型,得出新的预测结果。
回归预测分析使用方法
1 | 先修改原始数据 |
ycc是输出的结果
智能粒子群算法
求函数的极值,求最大值,好处是有动态变化图。
智能粒子群算法使用方法
1 | 粒子群算法基本步骤 |
小波异常提取
提取异常值,找到异常值之后,画出图像,即可找到异常值
小波异常提取使用方法
1 | 将数值赋值给cuspamax,然后再直接执行程序 |
灰色关联分析
构建各个指标之间的关联度,找到谁与标准数据的关联度最大
灰色关联分析使用方法
1 | 灰色关联分析步骤 |
小波特征提取
提取出一个图像中具有特征的部分
小波特征提取使用方法
1 | 直接执行代码 |
元胞自动机
元胞自动机(CA)是一种用来仿真局部规则和局部联系的方法。典型的元胞自动机是定义在网格上的,每一个点上的网格代表一个元胞与一种有限的状态。变化规则适用于每一个元胞并且同时进行。元胞的变化规则&元胞状态典型的变化规则,决定于元胞的状态,以及其( 4 或 8 )邻居的状态。
元胞自动机的应用
元胞自动机已被应用于物理模拟,生物模拟等领域。
元胞自动机的matlab编程
结合以上,我们可以理解元胞自动机仿真需要理解三点。一是元胞,在matlab中可以理解为矩阵中的一点或多点组成的方形块,一般我们用矩阵中的一点代表一个元胞。二是变化规则,元胞的变化规则决定元胞下一刻的状态。三是元胞的状态,元胞的状态是自定义的,通常是对立的状态,比如生物的存活状态或死亡状态,红灯或绿灯,该点有障碍物或者没有障碍物等等。
元胞和规则才构成了元胞自动机,主要适用于模拟地震火灾等情况,因为一处着火,会引燃其他地方,等等,附和元胞自动机的条件
元胞之间通过物理规则来演变的,没有很复杂的函数,每一个元胞根据规则来判断周围环境,然后再去执行。
所以元胞自动机不存在复杂的公式,只存在各种各样的规则



红色代表的是活的,黑色代表的是死的,开始运行后,最后得到的稳定结果,就是火灾模拟后得到的结果
线性规划
视频来源:
因为matlab只能求解线性规划问题的最小值,所以,求最大值的时候,要在前面加一个负号

先来做一道例题

1 | >> f=[-2;-3;5];%因为题目给的是最大值,所以要变为负号 |
答案,解得
1 | x = |
下面进行实际问题的解决


下面进行假设
线性规划模型使用方法
1 | 线性规划步骤 |
整数规划


一般都是纯整数规划
整数规划一般用于指派、运输问题
一般会有一个关于产量的限制
图论算法

将顶点、边、行驶时间看作数学概念,就转化为旅行售货员的问题了
V(G)是图上的顶点E(G)是图上的边
一般见到的都是有限图


图的矩阵表示,如果两点相连就是1,不相连就是0,构建一个矩阵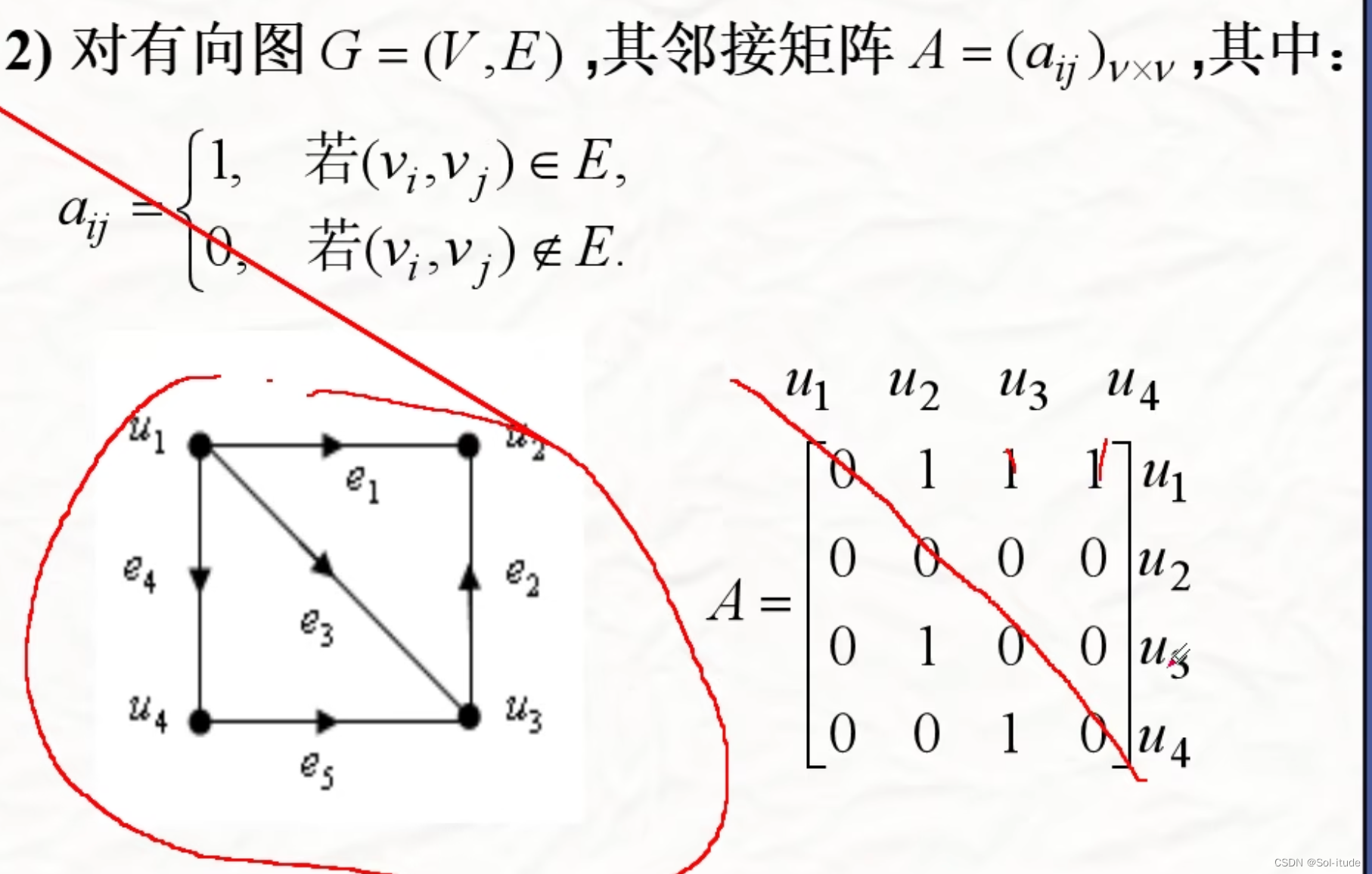
有指向的图就是u1指向u2,矩阵才为1,否则为0
加权的就按照给的权重计算,如果没有指向的话,则是∞
例:u2没有指向u1的线段,在矩阵中用无穷表示
关联矩阵,竖着写点,横着写线,如果之间相连了就是1,没有相连就是0

关联矩阵加上了方向,相连的正方向为1,反方向为-1
迹和简单链是点可以重合但是轨迹不能重合
二次指数平滑及时间序列预测使用方法

1 | function [Y,S1,S2,a,b] = expsmooth2(Yt,alpha,t) |
1 | 填写好Yt,alpha还有t,然后执行expsmooth2就可以进行预测了 |
赛题思路解析学习
1.如何读懂题和定位题目
- 抓关键词
- 输入+条件+输出
- 分析题目之间的关系
- 按领域分类
- 按数学模型分类

机场要求保证短途载客车的出租车司机收益,建立模型
第一问建立出的模型,在第二问带入数据。用结果分析第一问的灵敏度
安全的条件指的是不拥挤,利用排队论,设置其变量,保证其达到“不拥挤”这一条件,并且建立评价模型。
2.三次思路法
- 第一次思路,根据知识储备和经验的基本思路,不要一开始就去读文献;
- 二次思路,查资料,得到基本可行的思路框架,画流程图/思维导图;
- 三次思路,找资料+开拓思路+进行取舍;
想一道题的时间不要花太多时间,不能有太多完美主义,把题都做完,心里面不会那么慌;
3.和队友出现分歧怎么办
- 分工很重要;
- 考虑完成度和表现形式;
实战——19C
第一问:
- 找数据
- 经济学模型
- (航班数量的处理)聚类分析
第二问 :
- 搜集机场数据
- 模型结果和实际结果做对比
- 灵敏度分析
第三问:
- 单od多目标优化模型
- 效率+加权评价
第四问:
- 减少排队时间
- 再开一个车道或者不排队
- 经济上的直接补偿
每个模型必须要做灵敏度分析
关于如何做灵敏度分析:因为数据不是那么的准确,用控制变量的思想,横轴是你要变化的量,纵轴是要得出来的结果,
4.如何查找文献

学位论文选读有用的,论文直接从知网找就行。
找综述文章
论文该如何使用?
找关键词和思路,再通过自己的经验化简模型;
模型如何突破思路?
- 对数据的处理:异常、残缺,服从某种分布;
- 优化模型:目标函数、决策变量的巧妙切入;
- 分级评价-多级指标;
- 加权评判函数:不同的变量和权重(权重是自己来设计的);
- 阈值-特殊情况;
- 特殊情况特殊分析;
完善模型
- 数据处理:异常残缺等;
- 模型的特殊情况:找到特殊值进行分析;
下面是建模的主要步骤

算出数据之后一定要给出结论
在亚太杯结束后,我会把个人的思路和解决方案放出
详细请见另一篇新的笔记